基于Kaggle心脏病数据集的数据分析和分类预测
GitHub地址:暂未上传
研究背景:心血管疾病现状:心血管疾病是全球及我国人口死亡的主要原因之一,且患病人数众多。
研究意义:通过数据分析预测心脏病风险,有助于早期筛查、风险评估,为医生提供个性化预防和治疗方案。
研究内容:分析心脏病数据集,探索与心脏病相关的医学指标。建立分类模型预测心脏病风险。
项目流程: 数据预处理-> 模型训练与评估 -> 数据可视化
数据预处理:
数据清洗:
数据类型转换:对某些列的数据类型转换。例如,原始数据为数值类型,但需要将其转换为object类型,以便后续进行编码处理。
处理缺失值:通过填充均值或中位数处理缺失数据,确保数据完整。
特征工程:标准化:使用StandardScaler()对数据进行标准化处理,使所有特征的均值为0,标准差为1,确保不同特征在同一尺度上。
离散化:对离散型数据(如性别、胸痛类型等)进行转换,将其从数值表示转为字符串形式(例如:0表示女性,1表示男性)使数据更加直观和可解释。
独热编码:使用pd.get_dummies()对类别变量进行独热编码,避免类别数据对模型训练产生影响。
模型训练与评估:
模型训练:通过决策树和逻辑回归模型预测心脏病患病可能性。
决策树:采用决策树模型对心脏病进行二分类预测
算法:CART
分裂标准:基尼指数
使用训练集通过基尼指数优化划分规则
逻辑回归:
设置高精度容忍度 (tol=1e-10)
使用训练数据集进行建模
模型评估:调用 plotting(tree, y_test) 函数,对测试数据进行预测,绘制模型性能曲线(如ROC曲线)。
评估结果:
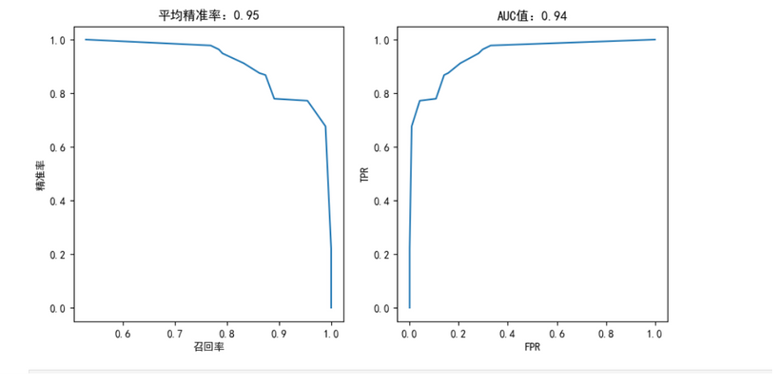

在本次研究中决策树模型表现较好,决策树模型的平均精准率为0.95,AUC值为0.94,召回率为0.78,表现出较强的分类能力,能够较为准确地识别出心脏病患者,尤其在AUC值上具有优势。
逻辑回归模型表现次之,逻辑回归模型的平均精准率为0.89,AUC值为0.88,略逊于决策树,但仍表现出良好的预测性能,尤其适合需要解释性较强的场景。
综合来看,决策树模型在心脏病预测任务中表现最佳,具有较高的分类准确性和较强的模型稳定性。
数据分析与可视化(展示部分)
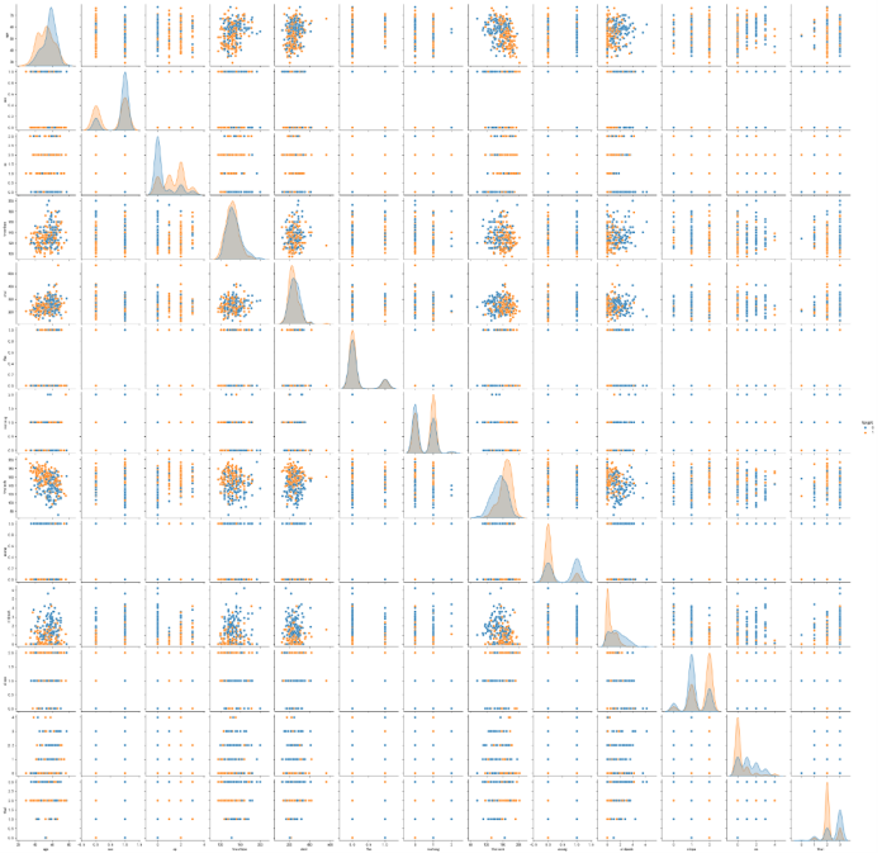
散点图矩阵分析特征分布及关系:通过散点图矩阵展示数值型特征两两之间的关系,并区分心脏病患病状态。
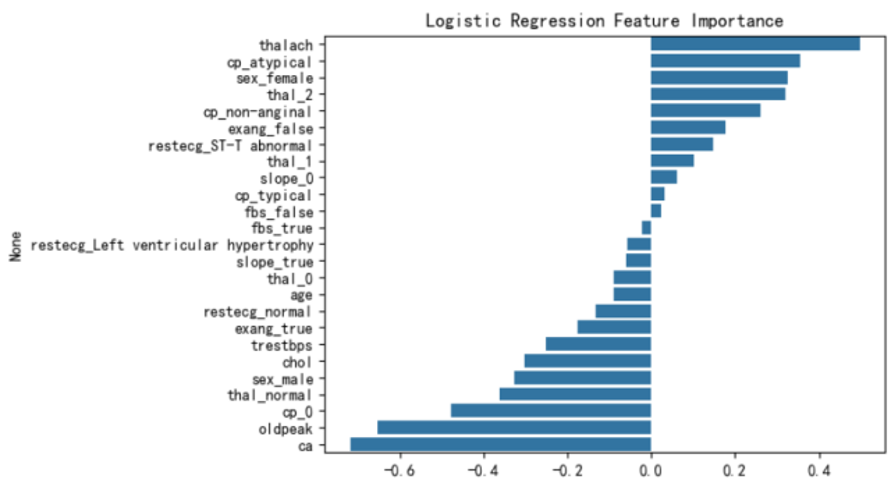
特征系数条形图分析:通过逻辑回归模型计算数据集中各特征的系数,分析每个特征对预测心脏病发生的影响大小和方向。